以前同様の記事を書いたことがあるが、内容をアップデートした。
WiresharkにはExport Objectという便利な機能があるが、ときどき、この機能でパケットからオブジェクトを上手く抽出できないことがある。以下のPCAPを例に見てみる。
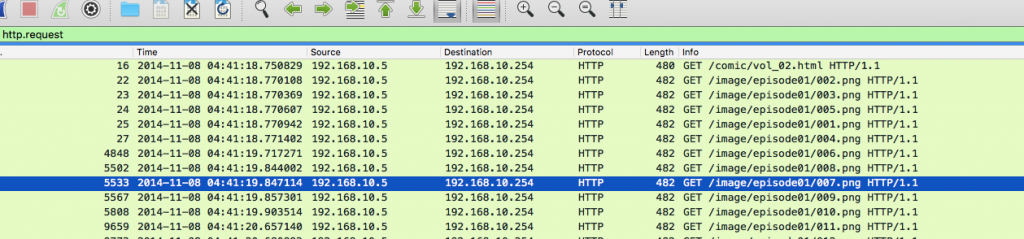
上記のPCAPから007.pngというファイルをExport Objectで抽出しようとすると。。
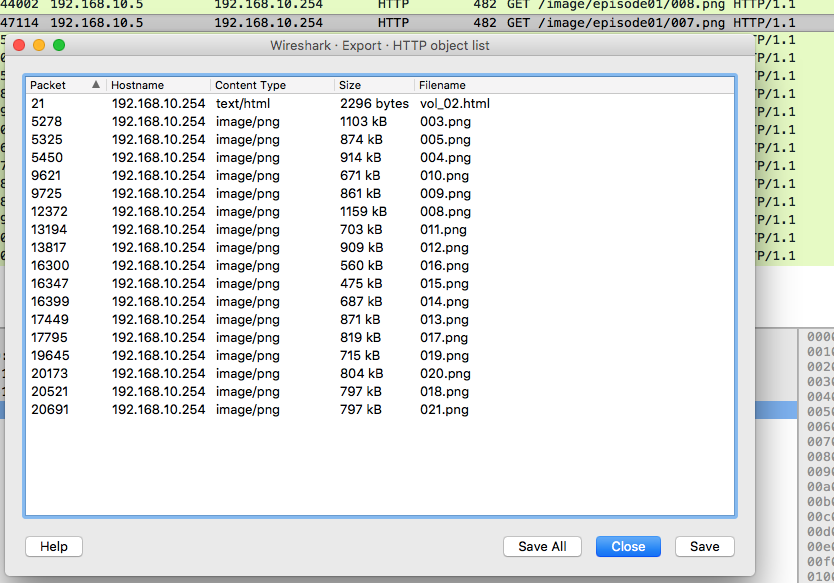
007.pngが欠けており抽出できない。なんらかの理由でExport Objectが007.pngを認識できていない模様。こういうときは手動でファイルを抽出する必要がある。
まず対象のオブジェクトが含まれているTCPストリーム番号を特定する。007.pngはTCPストリーム番号2に含まれている。
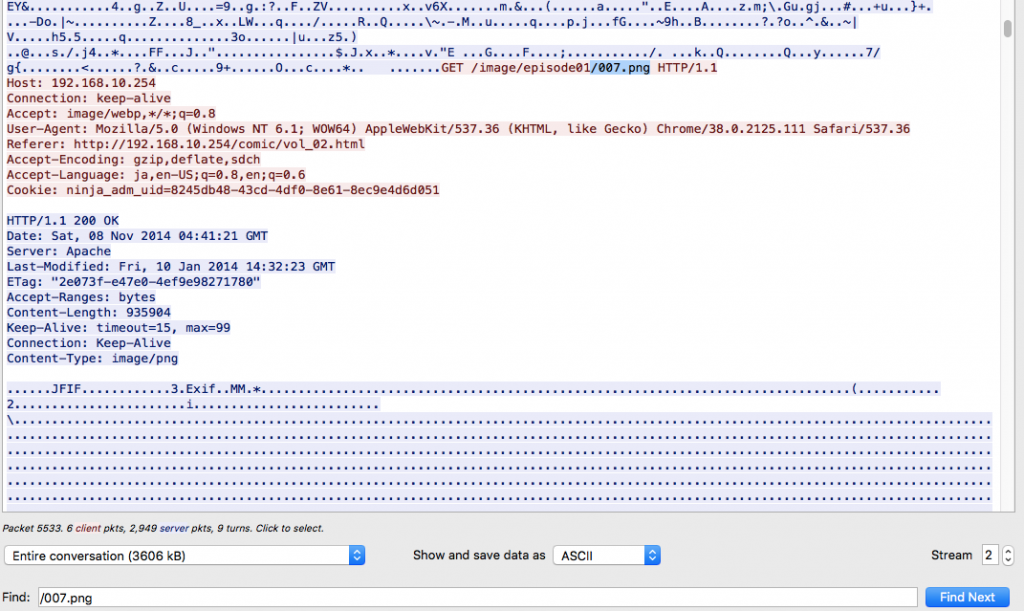
ちなみに、この通信ではHTTPの持続的接続が有効になっているので、TCPストリーム番号2には他にも003.png、013.png、021.pngのデータが含まれている。また上のスクリーンショットのとおり、ファイル名の拡張子は.pngとなっているものの、レスポンスのデータを見ると実際にはJPEG形式の画像ファイルである。

まずはTCPストリーム番号2でやり取りされたデータを保存する。TCP Streamウィンドウで対象のTCPストリーム番号を選択し、HTTPサーバーからのレスポンスでフィルタをかけて、Rawデータ形式で保存する。
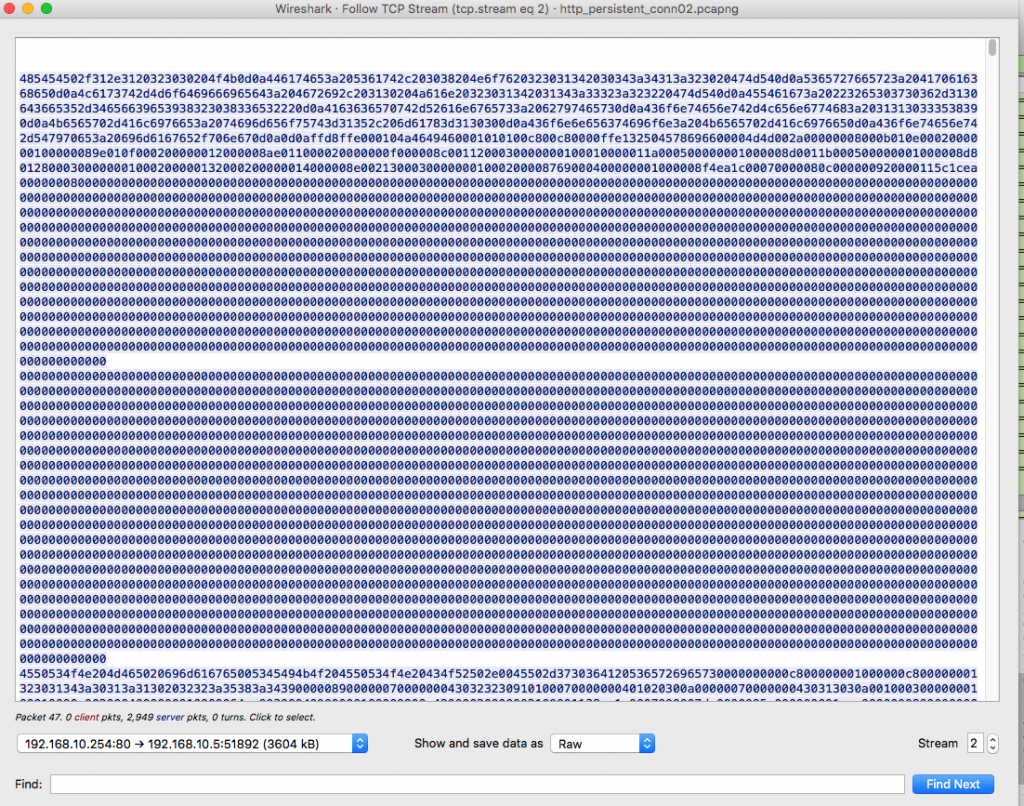
Rawデータのどこに007.pngが含まれているか確認する。まずは以下のコマンドでJPEGヘッダーを見つける。xxd raw.bin | grep -C2 JFIF
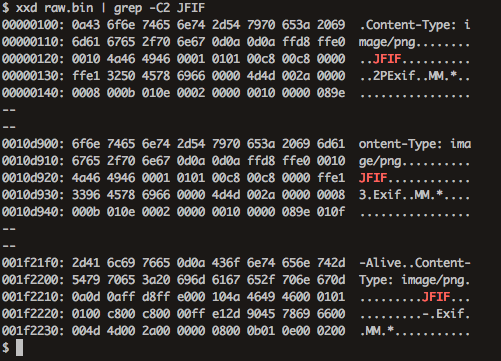
TCPストリーム番号2には合計で4つのJPEGファイルが含まれているはずだが、3つしか見つからない。これはxxdコマンドでデータをhex dump形式にした際のデータの並び方に原因がある。検索コマンドを以下のように変更してみる。xxd raw.bin | grep -C2 FIF
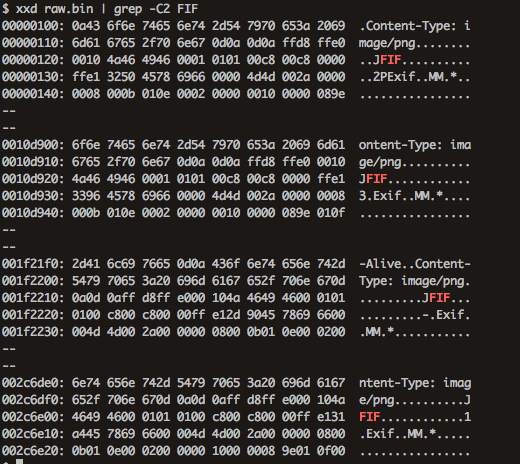
1回目の検索で結果が3つしか表示されなかったのは4つ目のJPEGヘッダ (JFIF)が2行にまたがっていたため。このように、データをhex dump形式にした際、必ずしも目的のデータがひと固まりになっているとは限らないため、必要に応じて検索の条件を変える必要がある。
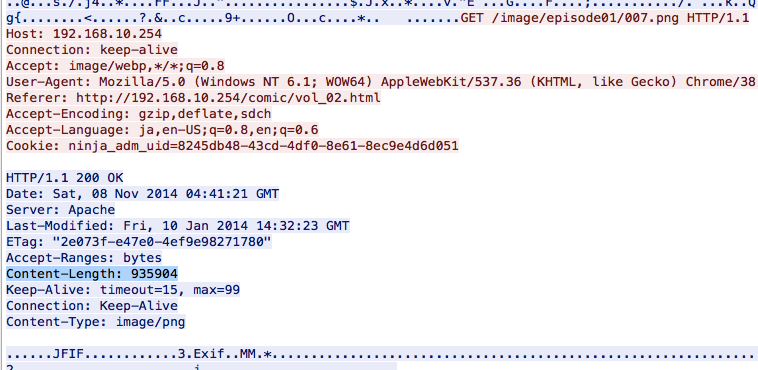
さて、007.pngは2つ目のHTTPレスポンスに含まれているので、上から2つ目のJPEGデータを抽出する。JPEGの先頭ヘッダーから何バイトまでのデータを抽出すれば良いのかは、HTTPレスポンスのContent-Lengthヘッダーの値を見れば分かる。
strings raw.bin | grep -i Content-Length
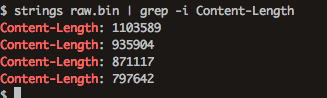
Content-Lengthヘッダーより、007.pngは935904バイトだと分かった。
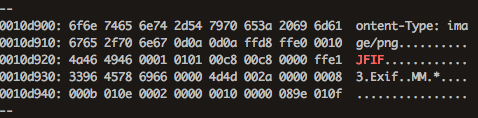
JPEGヘッダーの先頭バイトは ff d8から始まる。上のスクリーンショットより、ff d8はオフセット0x10d910から(0から数えて) 10バイト目の位置にある。
0x10d910 + 10 = 0x10d91a007.pngを抽出するにはオフセット0x10d91aから935904バイト抽出すれば良い。
以下のコマンドで抽出を行う。xxd -s 0x10d91a -l 935904 raw.bin | xxd -r >> out.jpg
※ファイルへのリダイレクトに>ではなく>>を指定している理由についてはこちらを参照。
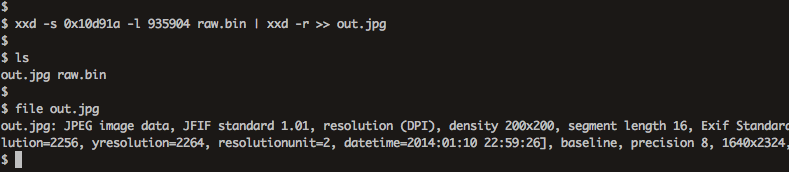
抽出したファイルをfileコマンドで確認したところ、JPEG画像ファイルとして認識していることが分かる。
念の為、抽出したファイルのフッターも確認してみる。JPEGの終了フッターはff d9。
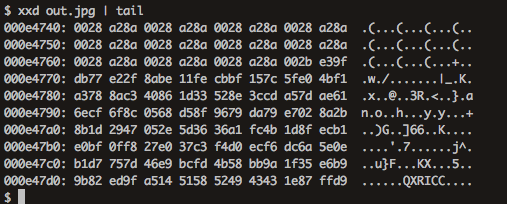
きちんとff d9でデータが終了していた。
最後に抽出したファイルを開いてみる。

画像は昔書いた漫画の1ページ。(どうでもいい)
まとめ
以下の点を押さえていれば上述した手順でPCAPからファイルを手動で抽出できる。
1. 抽出したいデータの先頭バイトの位置
2. 抽出したいデータの長さ、もしくは終了バイトの位置